The Birthday Paradox and Collisions in a Hash table
Opinions on probability vary among individuals; some embrace it, while others may not. Regardless, probability has the intriguing power to challenge our beliefs and make us consider things we might otherwise find implausible. For instance, would you be astonished to learn that the odds of winning the Euromillions lottery stand at 1 in 139,838,160? Such a slim chance may seem remarkable. Now, let your imagination wander to the probability of being selected as one of the eleven players in the Indian cricket team from a vast population of approximately 1.4 billion people. It’s truly a thought-provoking concept!
Before diving into hash collisions and the birthday paradox, let’s first explore what a hashtable is. Once we have a clear understanding, we can proceed to the main topic.
Hash table
Hash table is like a dictionary, or in other words it serves as a data structure designed for storing key-value pairs. What is the difference between a dictionary and a hash table then?

In a simple dictionary, we store the keys and the associated values, with each key pointing to its corresponding value. What is the issue with such a key-value store? Let’s illustrate this issue with an example: assume the keys range from 0 to 15, and key 0 is placed in location 1, key 1 in location 2, and so forth. Since keys can be inserted randomly into the dictionary, we must allocate a table large enough to accommodate 16 locations (which is the length of the longest key), even if we only have to store one key-value pair. Here the longest key is 16, which requires 4-bit to represent, and we need the number of locations equal to 2⁴.
Now, let’s say that we require a table that can store names and phone numbers. The name is the key, and the phone number is the value. Here the problem is that names can be quite lengthy, with each letter in the name being 8-bits (ASCII to binary). So the name ‘Indiana Jones’ is 104-bits, and assuming that it is the longest name that can come in, the table would require 2¹⁰⁴ locations. That means ~20 nonillion locations, and that is HUGE! Allocating memory on such a scale for the table is simply not feasible.
Here comes hash table to the rescue. First, we hash each name to generate a small digest, and this digest points to a location where the value to be stored. But, what exactly is a hash function? A hash function converts arbitrary length messages to a fixed length digest. Hash functions are one-way functions, which means irreversible. Hashing ≠ Encryption! You cannot retrieve the actual key from a hashed digest. For any small change in the input, a hash function should produce an entirely different output. An example of the MD5 hash function is shown here.
No hash function is perfect, which means there will be collisions. Collisions mean two different inputs produce the same hash output. A property called second pre-image resistance shows the collision resistance of a hash function.
Back to our dictionary problem…
Hash functions produce fixed-length digests of the original keys, and the size of the digest can be a predetermined value, equal to the size of the key-value store table. Now, we can store a key of any size in the table, as the hash function generates a fixed-length digest regardless of the size of the key. This allows us to create a table with a small number of locations, such as 16 (requiring only 4 bits to represent), to accommodate a large key like ‘Indiana Jones’ with 104 bits. That’s what a hashtable does. However, while mapping 104-bit keys to 16 locations, collisions will occur. This means that two different keys can be hashed into the same location in the table. This is because we are trying to map a 2¹⁰⁴ possibilities to a space of 2⁴.
How do collisions affect a hash table? Suppose one key K₁ points to location M and the associated value V₁ is stored in that location. Another key K₂ with a value V₂ also points to the same location, and K₂ is not yet added to the table. When we search for K₂ in the table, the table provides the value V₁, which is not correct.
So, how often can the collision happen? What is the probability of a collision? The misconception is that collisions in a hash table only happen when it’s nearly full, and some might believe that if the hash table is 25% full, collisions would occur with a 25% probability. However, this assumption is incorrect! That’s where the Birthday Paradox comes into the picture.
The Birthday Paradox!
There is a group of people. What is the minimum number of individuals needed in this group so that there is more than a 50% probability that two people share the same birthday? We know that there should be 365+1=366 people to have a 100% probability (ignoring leap year). So, is the answer 183 to have a probability greater than 50%? Incorrect!
Surprisingly, 23 people in a group are enough to have a probability greater than 50% such that two people share the same birthday! Is that hard to believe? Let’s see.
The probability that you share the same birthday with someone is 1/365, and the probability of having different birthdays is 364/365. However, when you consider all the possible pairings, the probability grows much faster. Remember, it is not about finding someone who has the same birthday as you, but rather finding any two people in the group who share the same birthday. In a group of 23 people, the number of possible pairings is (23 x 22/2) = 253.
The probability that two people do not have the same birthday is 364/365. We have 253 pairs, so the probability that none of the pairs share the same birthday is (364/365)²⁵³. Consequently, the probability of at least one pair sharing the same birthday is 1-(364/365)²⁵³ = 50.05%.
Probability of Hash table collisions
Let’s explore how birthday paradox works with hash tables and what is the probability of collisions in a hash table. Is it like 25% probability for a 25% filled hashtable? Let’s find out.
M is the number of locations in the hashtable and N is the number of items to be inserted. Then the probability that there is at least one collision among N randomly inserted keys is

Which equals:
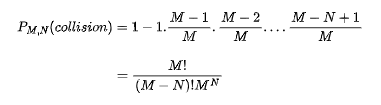
Using this equation, if we take M=365, and N=23, we get the probability of collisions as 50.07%, which is the probability of two people sharing the same birthday in a group of 23 people. And if you take N=57, the probability is 99.01%, which means it is almost certain that two people might share the same birthday in a group of 57 people.
Now, consider a hash table having 1000 locations, i.e; M=1000. Let’s examine the probability of collisions if the table is only 25% filled. i.e; N=250. The probability of collisions is incredibly as 99.99999999999984%! So it is almost certain that there will be a collision. This indicates that a collision is certain in such a scenario when the table only 25% filled.
Now, let’s calculate the probabilities for some specific values, considering M=1000.
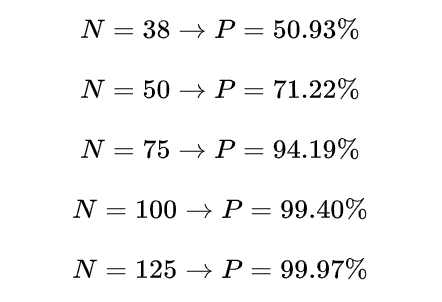
As you can see, 38 items are enough to have a probability of collision greater than 50% in a hashtable with 1000 locations. 125 items are enough to have a 99.9% probability.
Total Number of collisions in a hash table
We observed the probability of collisions. Perhaps some of you are intrigued to find out the total number of collisions if the number of elements to be inserted (N) is equal to the total number of locations (M).
Inserting an item into a hashtable is like picking a random item from the set of N items and throwing it into a set of M boxes. We cannot predict beforehand in which box the item will end up. It is possible that the item we throw ends up in a box that already has an item (which means a collision).
The first item we threw ended up in some box X. The probability that the second item ends up in the same box X as the first item is 1/M. Then the probability that the remaining (N-1) items end up in the same box X as the first item is (N-1)/M.
Assume there are no collisions in the first box where the first item landed. The second item we threw ended up in some box Y. The probability that the third item ends up in the same box Y as the first item is 1/M. Then the probability that the remaining (N-2) items end up in the same box Y as the first item is (N-2)/M.
This scenarios continue, and the average total number of collisions is:
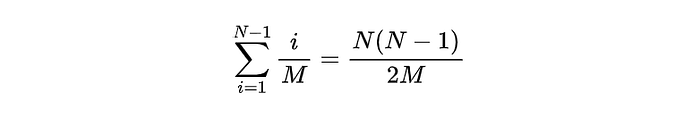
Let’s see the average total number of collisions possible when M=1000, and the number of items to be inserted is N.

So if we have a hash table having M locations and if the total number of items to be inserted is equal to the total number of locations in a hash table, then there will be M/2 total collisions, which is not a small number at all! So, the best way to reduce collisions is to make the hashtable larger (at least 1.3 times the number of items to be inserted).
References
[1]https://cseweb.ucsd.edu//~kube/cls/100/Lectures/lec17.hashing1/lec17.html
